Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Short description of portfolio item number 1
Short description of portfolio item number 2
Feature-based VSLAM often suffers from perspective and illumination change in GPS-denied parking lots. To this end, we use semantic features extracted from surround-view cameras to achieve long-term stable and robust localization. Thanks to accurate multi-camera calibration and IPM(Inverse Perspective Mapping), semantic features on the surround-view image can be projected on the ground to construct a more stable and consistent feature submap. In the back end, on the basis of the original tightly-coupled optimization consisting of IMU, wheel, and visual measurement, semantic features are added in a way similar to point-to-point residuals. At last, loop closure is detected to eliminate drift.
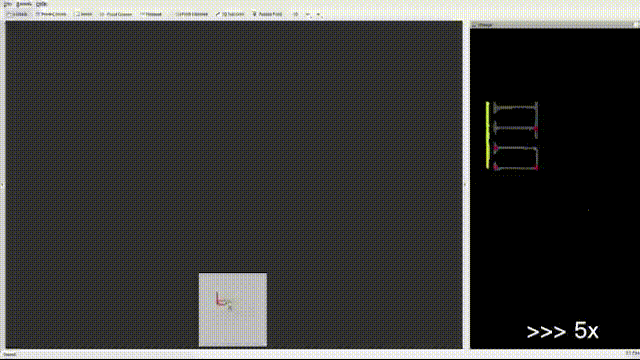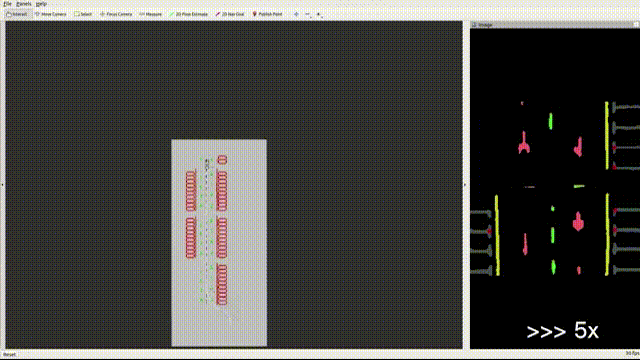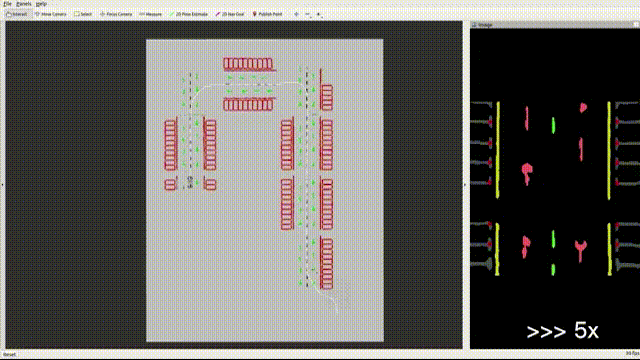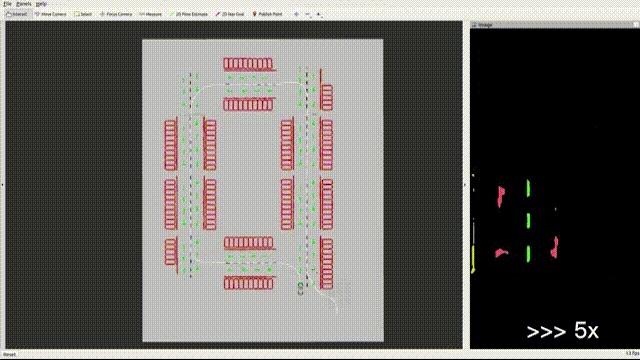
VINS has additional unobservable directions for localizing wheeled robots such as scale when a ground robot is constrained to particular motion. Furthermore, accelerometer measurements on the ground robot are greatly affected by noise compared to those on the aerial robot. For these considerations, Wheel measurements are integrated into VINS, where we reference some excellent open-source codes(such as VIW-Fusion) and implement wheel odometer pre-integration, residuals and extrinsic parameters calibration. On the other hand, GPU-accelerated feature extraction and optical flow methods are integrated into the system to accelerate the front end. The optimization in the back end is also improved to detect and remove(or reduce weights) the outliers of IMU and wheel pre-integrations and visual measurements. Fast-LIO2 is also integrated based on a factor graph. Furthermore, the Sparsification for graph optimization is on the to-do list.
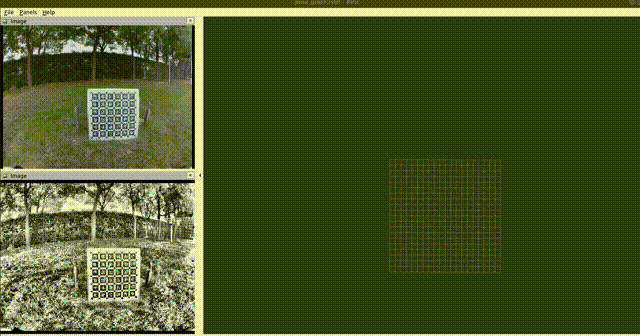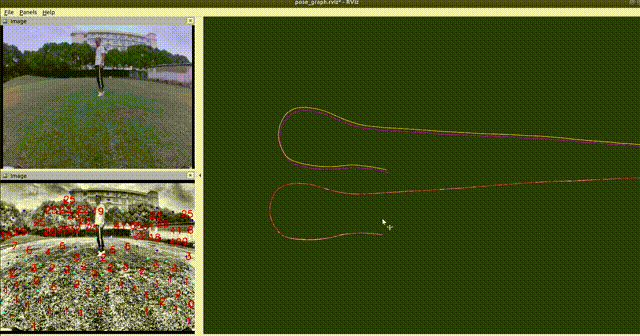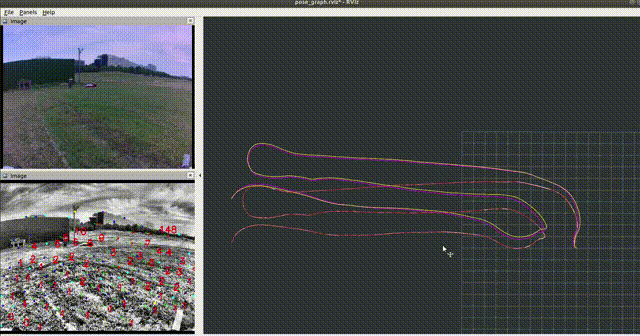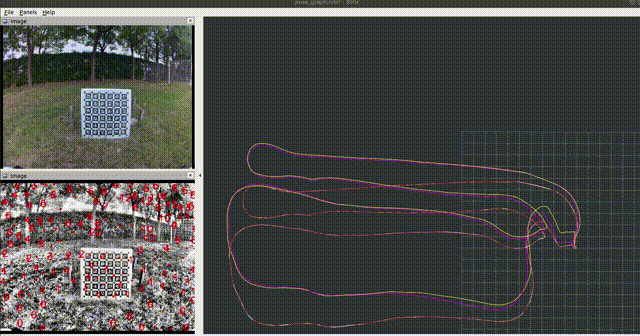
In an off-road environment, the assumption of horizontal ground is usually invalid, so IMU and wheel encoders are integrated into a closed form on SE3, which can be used to correct the distortion caused by motion. In addition, LPD-Net (reproduced by myself) is integrated into LIO-SAM to detect loop-closure with a coarse-to-fine sequence matching strategy, which helps to build a more accurate map for map-based localization. Then PLReg3D learns local and global descriptors jointly for global localization at the initial step. Finally, a loosely-coupled method based on the pose graph is applied to provide the robot with a robust and accurate pose.
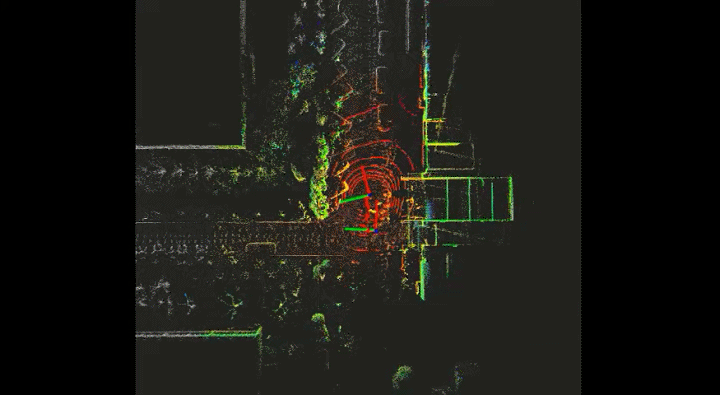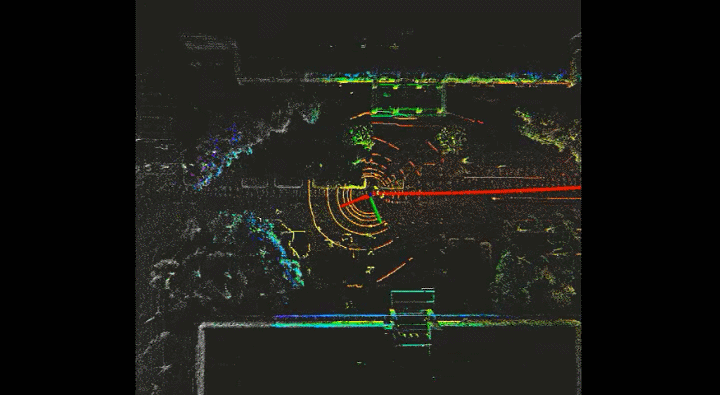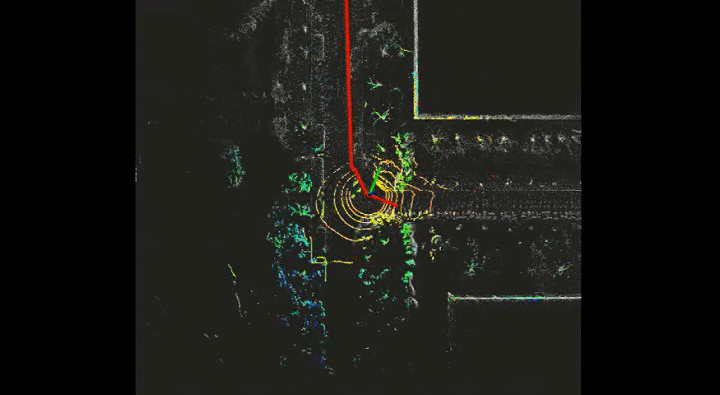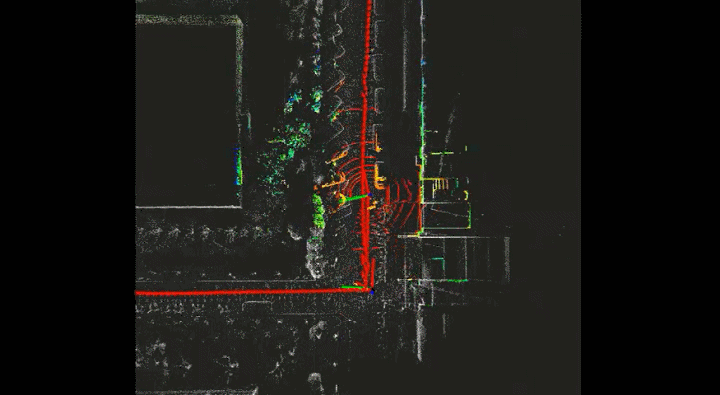
Current detection models in autonomous driving greatly rely on annotated data, which is expensive for the autonomous driving company. To this end, unlabeled large-scale collected data is considered to be exploited in self- or semi-supervised training. In this project, I adopt SESS, Mean Teacher, Pseudo-Label and 3DIoUMatch to my detection model. The picture below is the visualization of the labeled scan and unlabeled scan.

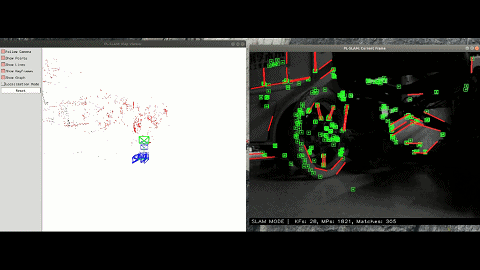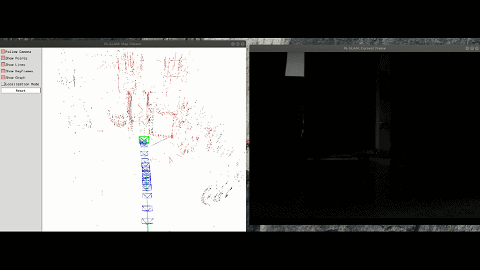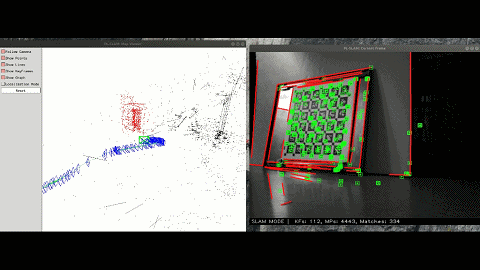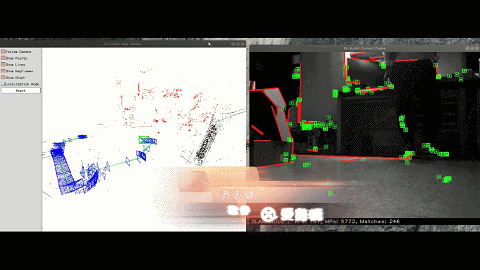
The framework of the program is based on ORB-SLAM3 and integrates other excellent work, such as VINS-Fusion, pl-slam, Structure-SLAM-PointLine, gf_orb_slam2 and semidense-lines. Line features are added to deal with low-texture environments; IMU and wheel encoder are added to deal with lighting variation and motion blur; Some work of Dr. Zhao is referenced for making SLAM cost-efficient.
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.