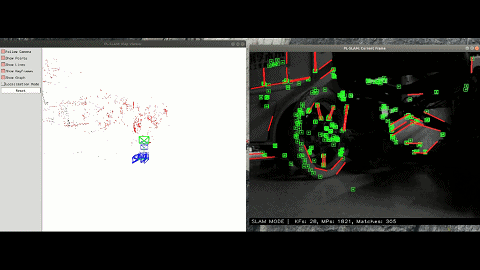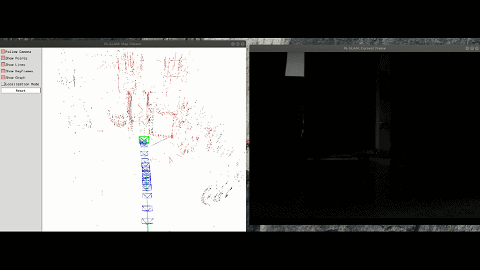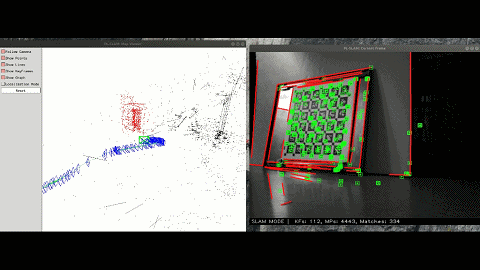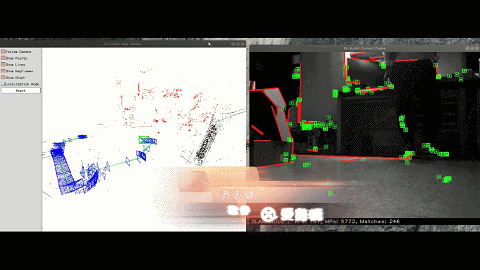
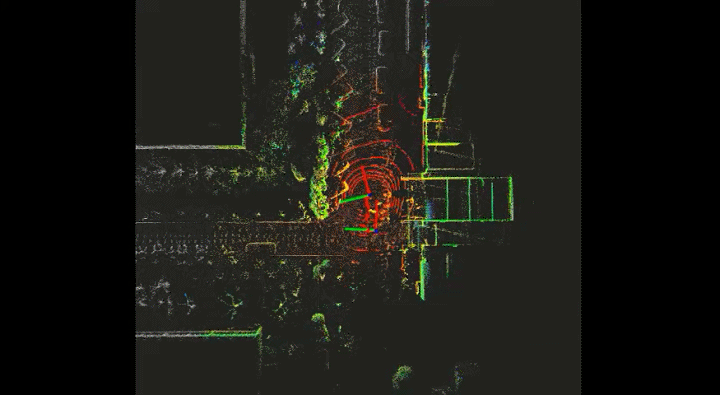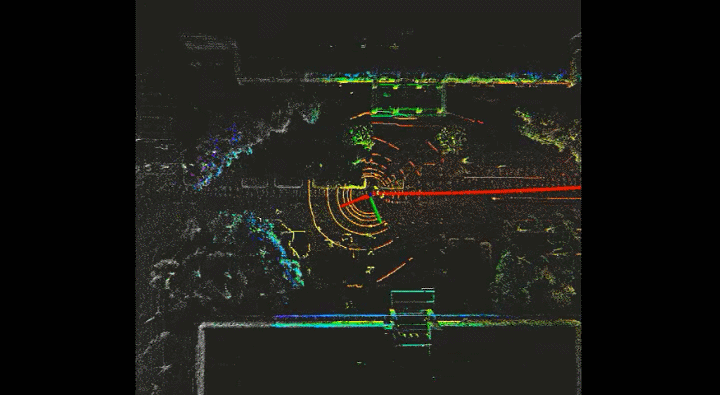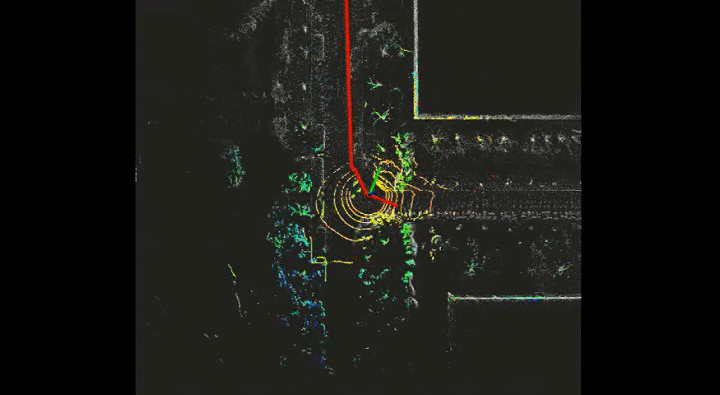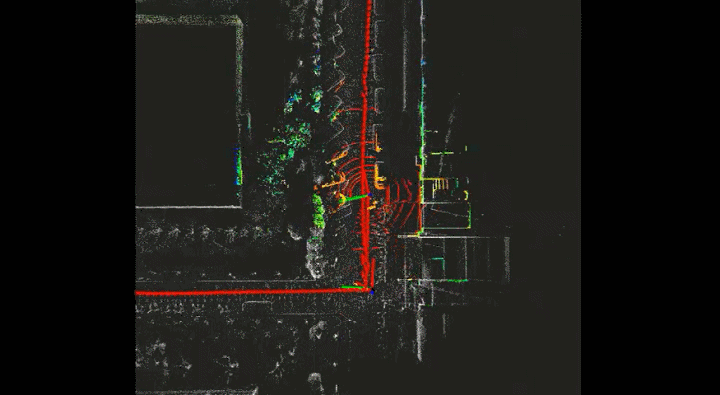Semantic VSLAM System with Inertial, Wheel, and Surround-view Sensors for Autonomous Indoor Parking
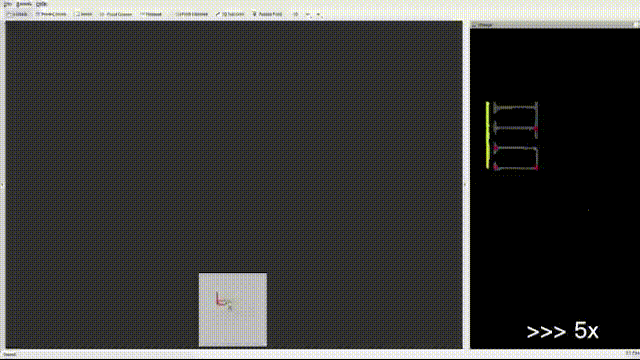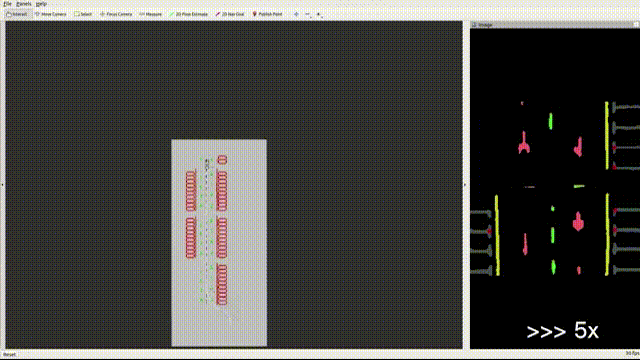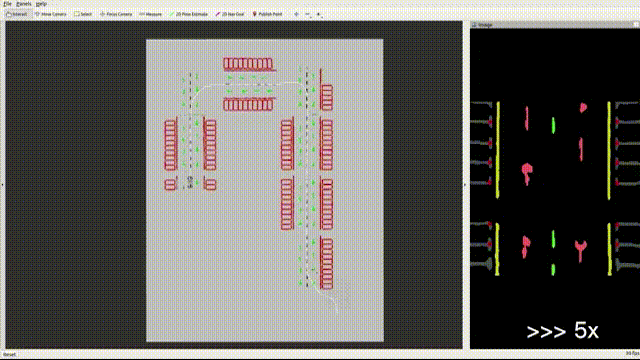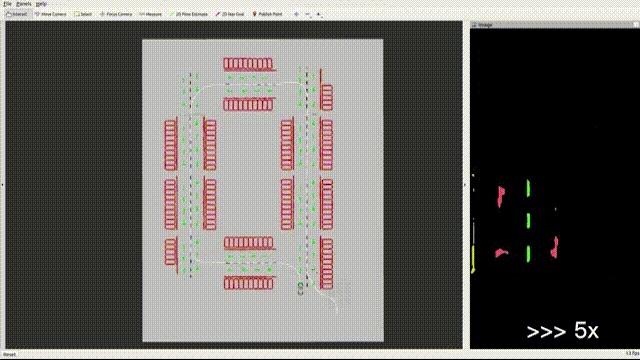
Feature-based VSLAM often suffers from perspective and illumination change in GPS-denied parking lots. To this end, we use semantic features extracted from surround-view cameras to achieve long-term stable and robust localization. Thanks to accurate multi-camera calibration and IPM(Inverse Perspective Mapping), semantic features on the surround-view image can be projected on the ground to construct a more stable and consistent feature submap. In the back end, on the basis of the original tightly-coupled optimization consisting of IMU, wheel, and visual measurement, semantic features are added in a way similar to point-to-point residuals. At last, loop closure is detected to eliminate drift.